2022.10.12
URLパラメータツール廃止後のSEOの扱い方
URLパラメータツール終了後、重複コンテンツエラーの正しい解決方法は?

2022年4月26日、Google は Search Console のURLパラメータツールの提供を終了しました。
URLパラメータツールの提供終了について詳しく:春のクリーンアップ: URL パラメータツール
Google はURLパラメータツールを使用しているユーザーにとって必要な対応はないとしていますが、URLパラメータツールの廃止にあたって、ご担当のウェブサイトのサーチコンソールで、以下のような「重複コンテンツ」に関するエラーが出てしまっていないでしょうか?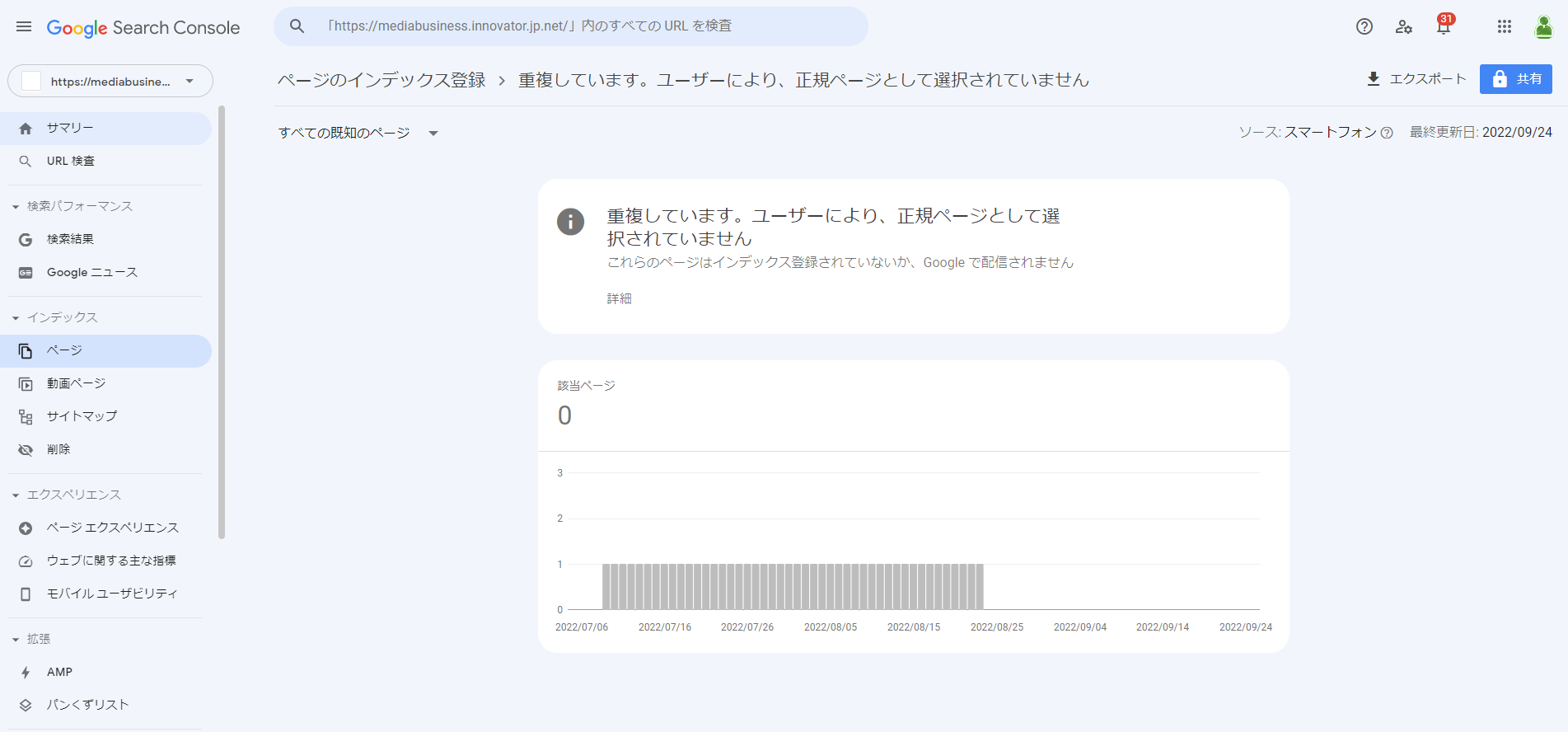
Google は特定のパラメータが付いた URL のクロールを制御したい場合には robots.txt を利用するように提案していますが、「重複コンテンツ」に関するエラーが出てしまった場合はどう対処すれば良いのでしょうか。
そのエラーを解決しようとした場合、robots.txtではない方法が適切なケースかもしれません。
本記事ではURLパラメータツールが廃止されたことで、コンテンツの重複エラーが発生してしまった場合の、正しいURL正規化の仕方について解説していきます。
例えば、下記のURLなどは「何もついていないURLと、パラメータが付いているURLで、内容が同じになってしまうURL」です。
パラメータが付いていないURL:
https://mediabusiness.innovator.jp.net/articles/983d98fa-1cae-4dc9-b4de-0908b263f61c
FacebookなどのSNSから流入する際に自動的に付与されるパラメータが付いたURL:
https://mediabusiness.innovator.jp.net/articles/983d98fa-1cae-4dc9-b4de-0908b263f61c?fbclid=xxxxxxxxxxxxx
GoogleAnalyticsなどで参照元を確認できるよう自主的に付与するパラメータが付いたURL:
https://mediabusiness.innovator.jp.net/articles/983d98fa-1cae-4dc9-b4de-0908b263f61c?utm_source=mail&utm_medium=dailymail&utm_campaign=221005
これらは本来同じページですが、うまくGoogle等の検索エンジンに認識させないと、「コピーコンテンツを複数のURLで公開している」と受け取られ、サーチコンソールで「重複コンテンツ」に関する警告が表示されてしまうことがあります。
robots.txt とは、サイトのルートディレクトリに設置し、クローラーの巡回を制御するファイルのことです。これにより、検索エンジンのクローラーに対して、サイトのどの URL にアクセスしてよいかを伝えることができます。
robots.txtは主に、クロールが問題を引き起こしている時や、ECサイトのようにページ数が大規模になるサイトで使用されます。クロールの制御を行う必要がないのであれば、robots.txt はSEOに強い影響を与えるため、不用意に使うべきではありません。
URL正規化し、重複コンテンツを解消する場合、robots.txt ではなく、rel="canonical" の使用が推奨されています。robots.txt で重複コンテンツを含むページをクロールできなくなると、そのページの評価を、正規ページに引き継ぐことができなくなるからです。GoogleはURL正規化、重複コンテンツの解消について下記のようにコメントしています。
正規化の目的で robots.txt ファイルを使用しないでください。(※1)
Google は、ウェブサイト上の重複コンテンツに対するクローラアクセスを禁止することは、robots.txt ファイルかその他の手段かにかかわらず、おすすめしていません。重複コンテンツを含むページをクロールできないと検索エンジンではそれらの URL が同じコンテンツを指していることを自動検出できないため、このような URL を独立した個別のページとして効率的に処理する必要があります。それよりも、重複コンテンツの URL について、検索エンジンによるクロールを許可する一方で、rel="canonical" リンク要素または 301 リダイレクトを使用して重複としてマークする方が適切です。(※2)
canonical とは、重複ページがある際に、クローラーに正規URLを示すために使用されます。canonical は、重複ページの<head>タグ内に以下のように記述します。
<link rel="canonical" href="正規URL">
この情報だけだと分かりにくいと思うので、より具体的に、重複コンテンツが生まれた際、どのようにcanonicalを使えば良いのかを解説します。
1:https://www.example.com(正規URL)
2:https://www.example.com?campaign=halloween2022
2のURLの「?」以降は、URLパラメータです。正規化のやり方は、2のタグ内に
<link rel="canonical" href="https://www.example.com">
と記述します。これにより、1のURLを正規化することができます。
URL正規化について詳しく:重複しているページの適切な正規 URL を Google が選択できるようにする
robots.txt は良くも悪くもSEOに強い影響を与えます。そのため、安易に robots.txt を使用するべきではありません。URLパラメータツールが廃止され、重複コンテンツの課題を抱えていた場合、robots.txt を使用するのではなく、canonicalを使用するべきです。
URLパラメータツールの廃止で、「重複コンテンツ」に関するエラーが出てしまった方に向け、少しでもお役に立てる情報があれば幸いです。
(※1)重複しているページの適切な正規 URL を Google が選択できるようにする | Google 検索セントラル
https://developers.google.com/search/docs/advanced/crawling/consolidate-duplicate-urls?hl=ja
(※2)重複コンテンツの作成を避ける | Google 検索セントラル
https://developers.google.com/search/docs/advanced/guidelines/duplicate-content?hl=ja